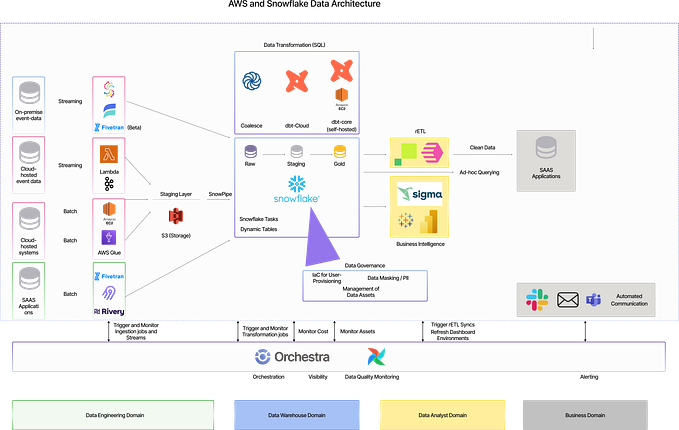
One of the main advantages of Data Lake over traditional Data warehouse is the separation of storage and compute.Due to this decoupling we can take advantage of cheap storage like S3 and only pay for the compute when we need to do any operation on the data. To work the compute and storage together in a cost-efficient way, many points to be considered while deciding how to store the data. Otherwise the cost for reading the data from storages like S3 might grow much higher than actual compute cost.
In this article we are discussing about optimizing the the total compute cost of typical Data Lake on AWS. Storage used is S3, compute engine used is Athena but it can be any pluggable query engine on S3.
Major cost elements involved in this architecture are
- Storage cost of S3 = ~ $23/TB/Month
- API cost of S3
- Athena Query cost = 5$/TB data scanned
Out of the three above, S3 API cost is the most tricky one. When there are hundreds of highly partitioned tables in S3 and lots of analytics is happening on top, major cost of Data Lake can be from S3 API cost, much more than storage and Athena cost. Here we are going deep to find a way to confirm that cost . We will see how to optimize the cost in next article.
Confirm S3 cost is significant
Obviously, first thing to do is to confirm S3 API cost is significant to be analysed. From AWS cost explorer(aws doc) see the trend of S3 cost for say last six/twelve months.

If it is in steep upward trajectory further check S3 cost components by grouping API operation

Now it is clear that S3 APIs like ListBucket is a significant part of S3 cost. Now we go further to see what is causing those huge API cost.
Identify S3 bucket and other details
Next is is to identify the S3 buckets involved in the heavy API calls. There are always multiple S3 buckets as part of Data Lake to separate data for business and technical reasons.
To find the culprit buckets, you can use AWS Cost and Usage Reports in Billing section.
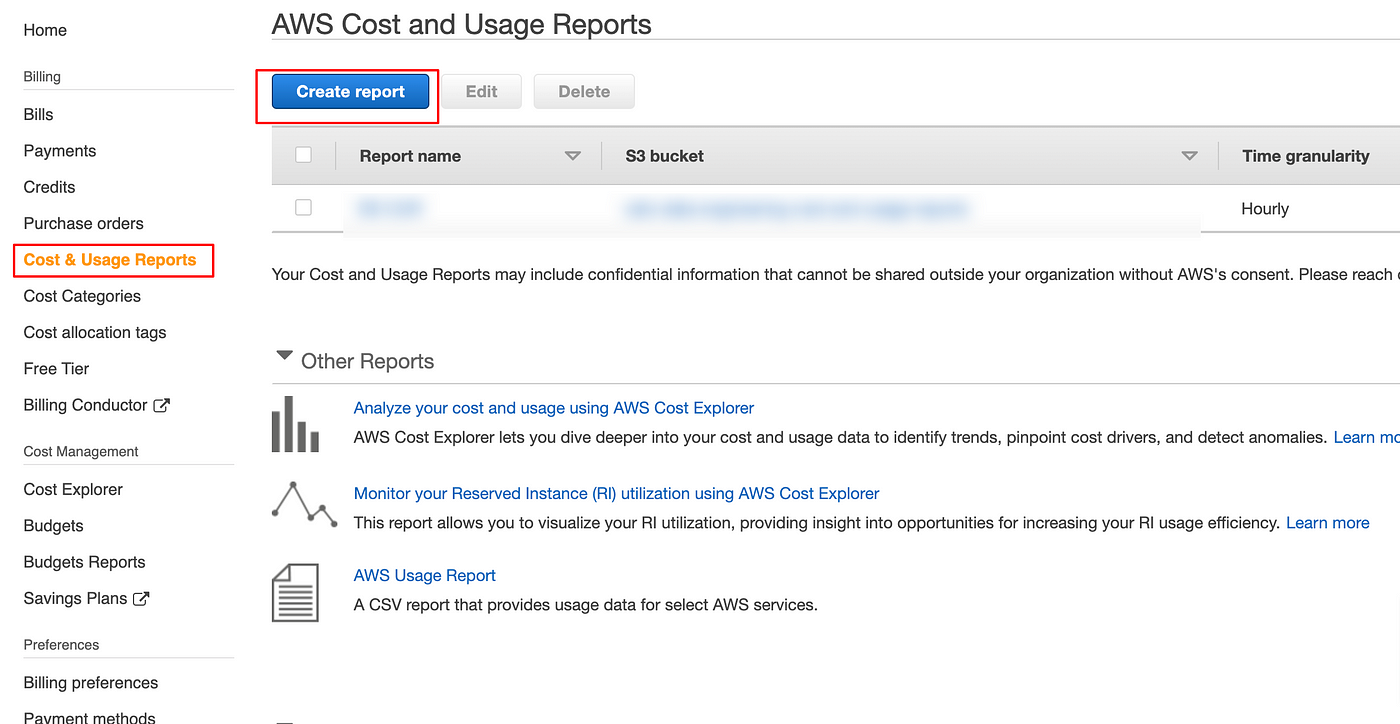
While creating the Report
- Better to use dedicated S3 bucket for storing your reports
- Make the granularity hourly
- and integrate to Athena
Once the report is created you can see the details of the report.

Go to that S3 prefix, you will find DDL to create Athena table on top of the report data. Download that file and run the SQL on Athena to create the table.Feel free to change the table name in the DDL file.

Once you created the table we can analyse the data. The data in S3 will be appended periodically, but remember to refresh table partition before you query new partition as shown below:
Now we have the list of S3 buckets causing the high bill. Say if a Data Lake raw data bucket is causing lot of API cost, then next step is to find which data-set or Athena table is causing that much API requests. Let’s see how to find that level of details.
API requests at table/prefix level
To go deeper to the S3 bucket at a prefix level, first thing to do is to enable S3 server access logs for the bucket. Then will create Athena table on top that.
Enable the access logging can be done from AWS console, It can be found in bucket properties as shown below.Server access logging is free of cost

While providing target path, don’t give same bucket , otherwise it will be an infinite loop. Once you enabled the logging check the target path after sometime to make sure log files are present in the folder. If not, it will be mostly permission issues — see aws doc for further guidance.
If data is present, wait for two three days to get enough data. Make sure your scheduled pipelines are running as usual and not a lot of heavy adhoc queries are running on top the data-sets in the bucket during this time as we ant to see what happens in a typical day.
Once enough data generated create Athena bucket as below. Change S3 location to the log target path.
This table will be very slow to read, so next create another Parquet table with necessary columns :
Then write an SQL to find APIs called for specific prefixes.
- Here prefix for specific table is in the format s3bcucket/databases/<db_name>/<table_name> . Change the SQL for the specific format.
REST.GET.BUCKEToperation is referring to ListObjects read more here
Result will looks like this:

The result has prefix level API counts. We can have any slice ad dice on the data like which user is causing most calls etc..
Conclusion
Now the data set causing most S3 API cost is identified. In the next article we will discuss how to optimize the cost.